
光学前沿动态
OPTICS FRONTIERS
02
2026
-
07
国家天文台发布 StarCLR 时域大模型
作者:
近日,中国科学院国家天文台发布面向光变曲线的时域天文基础模型 StarCLR,让来自不同巡天的光变曲线开始“说同一种语言”。该模型通过对比学习和大规模无标签预训练,从采样频率、观测时长和观测波段各异的数据中提取更加稳定、本征的时序特征,并在涵盖近 30类变星的分类任务中取得 92%到99%的微观平均F1分数。在 TESS 数据上完成预训练后,StarCLR 可有效迁移至 Gaia 和 ZTF 数据,展现出突出的跨巡天泛化能力,为多源时域观测的统一建模、联合分析及未来大规模巡天数据处理提供了新的技术路径。
光变曲线记录了天体亮度随时间的变化,是识别变星类型、研究恒星及双星演化、描绘银河系结构和构建宇宙距离尺度的重要观测依据。然而,不同巡天在观测波段、采样节奏、时间跨度和测光精度等方面差异显著。同一颗变星在不同巡天中的光变曲线往往呈现出不同的观测形态,使传统针对单一数据集训练的分类模型难以直接迁移。
针对这一难题,研究团队提出 StarCLR 模型,重点解决不规则采样光变曲线的统一表征问题。模型借鉴人工智能基础模型中的表征学习思想,利用对比学习将不同观测条件下具有相似物理性质的光变曲线映射到相近的特征空间。类似于自然语言模型能够将不同语言中的相同语义映射到统一空间,StarCLR 也能够尽量分离天体本征变化与巡天采样模式、仪器响应等观测因素,从而获得更具迁移能力的时序表示。
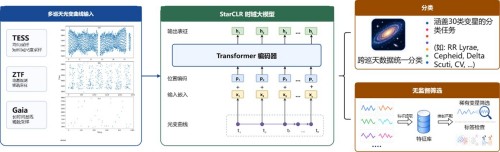
不同于围绕单一分类任务从头训练的传统模型,StarCLR 首先利用大规模无标签光变曲线进行预训练,再将学到的通用表征迁移至不同下游任务。研究团队在 TESS 数据上完成模型预训练,并在 Gaia 和 ZTF 数据集上开展跨巡天验证。在涵盖近 30类变星的分类任务中,StarCLR 在不同数据集和实验设置下取得了 92%到99%的微观平均F1分数,不仅能够精细区分多种光变形态相近的变星类型,也表现出良好的跨巡天泛化能力。 这一结果表明,StarCLR 学到的不只是某一巡天特有的采样模式,而是能够在一定程度上捕捉变星光变曲线中更稳定、更本征的时序结构。借助这种通用表征,未来面对新的巡天数据时,有望减少重复构建特征体系和重新训练模型的成本,提升多源时域数据协同分析的效率。
除变星分类外,StarCLR 的表征还可进一步拓展至异常天体发现、相似光变曲线检索、小样本稀有天体识别以及其他时域天文任务。随着 LSST、墨子、梦飞等巡天持续产生海量观测数据,时域天文学正由面向单一任务的算法开发,逐步迈向可迁移、可扩展的基础模型研究。StarCLR 为连接不同巡天观测系统提供了一种新的可能,也为下一代时域天文数据的自动化处理和科学发现奠定了技术基础。
相关成果已发表于《天体物理学报》(ApJ),该工作由中国科学院国家天文台与之江实验室合作完成,由国家天文台人工智能推进委员会支持。中国科学院国家天文台与西藏大学联合培养研究生丁俊瑶为论文第一作者,陈孝钿研究员为通讯作者。
来源:国家天文台
最新动态
感谢您访问崇帆科技官方网站,如有合作意向或建议,请通过以下方式联系我们,我们会尽快给予回复,谢谢!
移动版

官方公众号